我们总是东张西望,唯独漏了自己想要的,这就是我们至今难以如愿以偿的原因。
有时候我们需要单点修改区间查询的小常数线段树,这就是zkw线段树。
zkw整个学习时间不超过5分钟。
zkw线段树学习笔记
Note:注意使用位运算优化常数。
zkw线段树建树的方式就是首先输入叶子结点的信息然后再一路向上传递信息,直到根结点。这时问题又来了….Where is the first leaf???我怎么找到第一个叶子在哪?假设我们的单点数量(叶子数量)正好是 $2^k$ ,那么我们手里就握着一个满二叉树了,这样我们就能轻松地计算出来第一个结点的位置是: $2^{k}$ 。但是如果不是满二叉树怎么办呢?没有关系,现在的电脑内存不是问题!直接开成满二叉树就好啦~~。这样一来,第一个叶子结点的位置就是: $2^k+1(k=\lceil\log_2N\rceil)$
(见代码下的解释),也就是比 大的最小的 $2^k$。找到叶子结点之后,直接输入叶子结点信息,然后一个一个结点上传信息到父亲结点。于是我们得到了这样的代码:
1 | inline void Maintain(int x) { |
简洁明了,注意从M+1开始比较好
NOTICE:看到评论中很多朋友问为什么要在 $M+1$ 处开始输入。我这里统一解释一下,评论中我所说的也有问题(这里说声抱歉,昨天一天都在路上,没有时间思考….),以文章此处为标准好啦。
建议先看完下一节(区间和计算)再来看此处有助于理解。从 $M+1$开始是为了进行区间查询。
假设我们查询的区间就是 ,这时为了进行查询我们会将
转换为
,看上去没有区别,其实是有区别的。由于位于
上的数字是否能被统计上与左端点位置相关$L=M+1-1=M$,如果从
开始输入会导致查询时统计不到位于
上的信息,因为
初始位置就是第一个叶子的位置了$L=M$ .. 但是如果换成
开始,查询时
的位置依旧是 $L=M+1-1=M$ ,但是第一个叶子的位置在 $M+1 $上,这样就能够统计到那个叶子上的信息啦。因此要从 $M+1 $ 开始输入信息。
更新操作不难,就是直接找到叶子然后向上pushup即可
1 | inline void Update(int pos,int v) { |
接下来是略有难度的区间查询
我们需要把L,R分别向左向右一个位置,然后查询。
Q:为什么?
Ans:就是得这样啊。。不然你端点开始就查错了。查询原理如下:
当遇到区间和查询时,问题双来了….传统线段树通过递归查询需要加和的区间最后统计所有的和,但是Zkw线段树….没法从顶上找到需要加和的区间啊QwQ….怎么办呢?但是换个方向思考…从底向上,查询区间为 $[L,R]$,我们只能知道当前区间是否在查询区间内,即:如果当前查询区间左端点 $L$向结点是线段树某个结点的左儿子且 $R-1 \ne L$(即右端点指向结点不是左端点指向结点的兄弟),那么它的兄弟结点$ L+1$ 必然在查询区间内。同理,如果 $R$所指向结点的兄弟结点不是$L$,那么它的兄弟结点必然包含在查询区间内。如图:
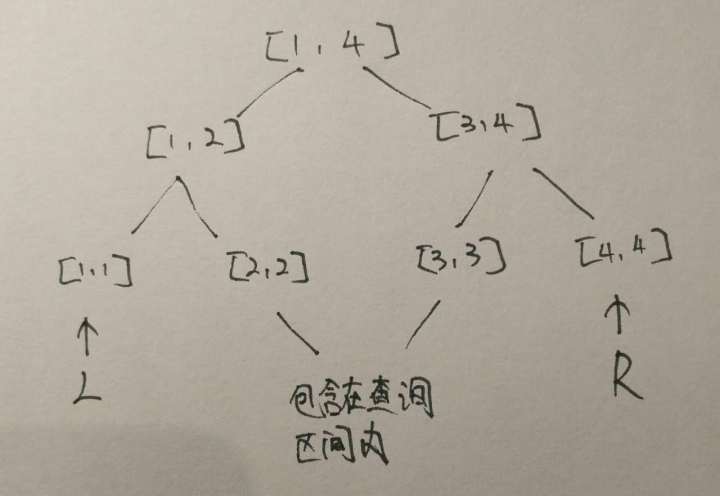
讲真这个东西确实不是很自然,主要是考虑$1$~$n$查询,其边界这样做依旧正确,就行了。
1 | inline int Sum(int l,int r) { |
这样zkw线段树就基本上介绍完毕了,可以试试优化天使玩偶了!
果然依靠zkw线段树在72秒内跑过了
不过还要在想想zkw的各种边界。
AC code:
1 |
|
刚刚又去研究了下zkw线段树,发现比如它维护长度为5的序列,如果你画图会发现这颗线段树每个节点向下不再是中点二分维护区间了,比如上述就是根的左子节点维护1~4,右子节点维护5,但是无论是正确性还是时间复杂度都没有问题,因此对于这种数据结构的研究也就到此为止了。
开始复习点化学到9点。。。